Контейнеры и гипервизоры - в чем разница?
КОНТЕЙНЕРЫ ПРОТИВ ГИПЕРВИЗОРОВ -ВСЕ ДЕЛО В ПЛОТНОСТИ
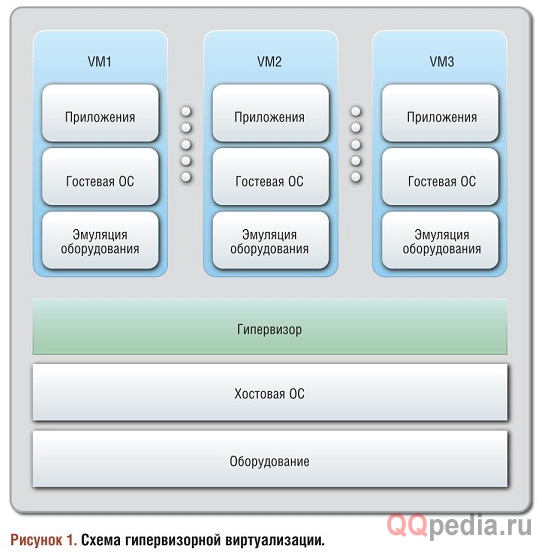
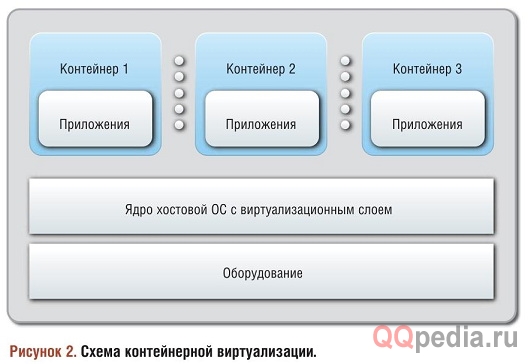
Гипервизор работает следующим образом (см. Рисунок 1): операционная система хоста эмулирует аппаратное обеспечение, поверх которого уже запускаются гостевые операционные системы. Это означает, что взаимосвязь между гостевой и хостовой операционными системами следует «железной» парадигме: все, что «умеет» делать оборудование, должно быть доступно гостевой ОС со стороны хостовой. Напротив, контейнеры (см. Рисунок 2) — это виртуализация на уровне операционной системы, а не оборудования, то есть каждая гостевая ОС использует то же самое ядро (а в некоторых случаях — и другие части ОС), что и хостовая. Это дает контейнерам большое преимущество: они меньше и компактнее гипервизор-ных гостевых сред, поскольку у них с хостом гораздо больше общего.
Другой большой плюс — значительно большая эффективность контейнерной виртуализации в отношении совместного использования ресурсов, так как для нее контейнеры — это всего лишь управляемые ресурсы. К примеру, когда Контейнер i и Контейнер 2 работают с одним и тем же файлом, ядро хоста открывает этот файл и размещает страницы из него в страничный кэш ядра, которые затем передаются Контейнеру i и Контейнеру 2: если оба «хотят» прочитать одни и те же данные, они получают одну и ту же страницу. Если же гипервизорным виртуальным машинам VMi и VM2 надо выполнить такую же операцию, то сначала сам хост открывает запрашиваемый файл (создавая страницы в своем страничном кэше), а затем еще и каждое из ядер VMi и VM2 выполняет аналогичное действие. Таким образом, в процессе чтения машинами VMi и VM2 одного и того же файла в памяти существует целых три одинаковых страницы (по одной в страничном кэше хоста и в ядрах VMi и VM2), потому что они не «умеют» одновременно использовать одну и ту же страницу, как это делают контейнеры.
Дело даже не столько в «чтении» файлов, сколько в возможности использовать одну копию исполняемых файлов и разделяемых библиотек (shared libs) в разных контейнерах. В обычной системе, если два или более процесса обращаются к одной и той же разделяемой библиотеке (например, НЬс), ее код присутствует в памяти только в одном экземпляре. Это относится и к исполняемым файлам, и к сегментам немодифицируемых данных, что позволяет существенно снизить требования к размеру оперативной памяти. Так как контейнеры используют единое ядро, вышеописанный механизм при некоторых условиях распространяется и на них, что приводит, в частности, к повышению плотности их размещения, которая и без этого механизма изначально выше, чем у виртуальных машин, поскольку отсутствуют множественные копии ядра.
В результате у контейнеров плотность (количество виртуальных сред, которые можно запустить на сервере) может быть до трех раз выше, чем у виртуальных машин, а на одном сервере вполне может размещаться несколько сотен контейнеров. Столь высокая плотность — одна из главных причин популярности контейнеров на рынке хостинга виртуальных выделенных серверов (VPS). Если на одном и том же сервере можно создать в три раза больше VPS, то в расчете на один VPS затраты снижаются на 66%, что для такого низкомаржинального бизнеса, как хостинг, иногда равно разнице между убыточностью и прибыльностью.
Конечно, не все идеально в мире контейнеров. Например, из-за совместного использования ядра на одном сервере нельзя запускать разные гостевые ОС (например, на системе с Linux-контейнерами невозможно запустить FreeBSD или Windows, но разные дистрибутивы Linux -сколько угодно). Поэтому Windows и Linux на одном и том же сервере (что для гипервизоров не проблема) не работают. Однако по крайней мере в случае Linux этот недостаток можно смягчить за счет использования интерфейсов ABI и библиотек: благодаря этому появляется возможность запускать на одном сервере контейнеры с различными дистрибутивами Linux, но одновременно сокращается общая для этих контейнеров часть ресурсов. В максимальной же степени преимущества контейнеров проявляются в однородной среде.
ИСТОРИЯ КОНТЕЙНЕРОВ
В 2005 году компания Google занялась задачей массового предоставления Web-сервисов, а именно искала способ эластичного масштабирования ресурсов в своем центре обработки данных, чтобы каждый пользователь имел возможность получить достаточный уровень сервиса в любой момент, независимо от текущей загрузки, а оставшиеся ресурсы можно было использовать для служебных фоновых задач.
Поэкспериментировав с традиционной виртуализацией, сотрудники Google сочли ее не подходящей для решения этой задачи. Главной проблемой стали слишком большие потери производительности (соответственно, плотность оказалась слишком низкой) и недостаточно эластичный отклик для динамического переконфигури-рования системы под изменившуюся нагрузку для массового предоставления Web-сервисов.
Последний пункт очень важен, потому что заранее предсказать, сколько запросов — десятки, сотни тысяч или даже миллионы — будут обслуживать Web-сервисы, невозможно. Но пользователи всегда ждут немедленного отклика (а это означает, что разница между нажатием кнопки и появлением результата на экране должна быть незаметна для глаз) независимо от того, сколько именно других людей в этот же момент работают с сервисом. Среднее время загрузки гипервизорной виртуальной машины — десятки секунд, поэтому такой тип виртуализации не подходит для этой задачи.
В то же самое время одна группа разработчиков экспериментировала с Linux и концепцией, основанной на механизме cgroups — так называемые контейнеры процессов. Google наняла этих специалистов для работы над контейнеризацией своих ЦОД с целью решения проблемы эластичности при масштабировании. В январе 2008 года часть технологии cgroup, используемой Google, была перенесена в ядро Linux. Так родился проект LinuX Containers (LXC). Тем временем Parallels выпустила версию своей виртуализации Virtuozzo с открытым исходным кодом под названием OpenVZ. В 2011 году Google и Parallels пришли к соглашению о сотрудничестве в области контейнерных технологий. Результатом стал релиз ядра Linux версии 3.8, представленный в 2013 году. В нем были объединены все актуальные на тот момент контейнерные технологии для Linux, что позволило избежать повторения болезненного разделения ядер, как в случае с KVM и Хеп.
Гипервизор работает следующим образом (см. Рисунок 1): операционная система хоста эмулирует аппаратное обеспечение, поверх которого уже запускаются гостевые операционные системы. Это означает, что взаимосвязь между гостевой и хостовой операционными системами следует «железной» парадигме: все, что «умеет» делать оборудование, должно быть доступно гостевой ОС со стороны хостовой. Напротив, контейнеры (см. Рисунок 2) — это виртуализация на уровне операционной системы, а не оборудования, то есть каждая гостевая ОС использует то же самое ядро (а в некоторых случаях — и другие части ОС), что и хостовая. Это дает контейнерам большое преимущество: они меньше и компактнее гипервизор-ных гостевых сред, поскольку у них с хостом гораздо больше общего.
Другой большой плюс — значительно большая эффективность контейнерной виртуализации в отношении совместного использования ресурсов, так как для нее контейнеры — это всего лишь управляемые ресурсы. К примеру, когда Контейнер i и Контейнер 2 работают с одним и тем же файлом, ядро хоста открывает этот файл и размещает страницы из него в страничный кэш ядра, которые затем передаются Контейнеру i и Контейнеру 2: если оба «хотят» прочитать одни и те же данные, они получают одну и ту же страницу. Если же гипервизорным виртуальным машинам VMi и VM2 надо выполнить такую же операцию, то сначала сам хост открывает запрашиваемый файл (создавая страницы в своем страничном кэше), а затем еще и каждое из ядер VMi и VM2 выполняет аналогичное действие. Таким образом, в процессе чтения машинами VMi и VM2 одного и того же файла в памяти существует целых три одинаковых страницы (по одной в страничном кэше хоста и в ядрах VMi и VM2), потому что они не «умеют» одновременно использовать одну и ту же страницу, как это делают контейнеры.
Дело даже не столько в «чтении» файлов, сколько в возможности использовать одну копию исполняемых файлов и разделяемых библиотек (shared libs) в разных контейнерах. В обычной системе, если два или более процесса обращаются к одной и той же разделяемой библиотеке (например, НЬс), ее код присутствует в памяти только в одном экземпляре. Это относится и к исполняемым файлам, и к сегментам немодифицируемых данных, что позволяет существенно снизить требования к размеру оперативной памяти. Так как контейнеры используют единое ядро, вышеописанный механизм при некоторых условиях распространяется и на них, что приводит, в частности, к повышению плотности их размещения, которая и без этого механизма изначально выше, чем у виртуальных машин, поскольку отсутствуют множественные копии ядра.
В результате у контейнеров плотность (количество виртуальных сред, которые можно запустить на сервере) может быть до трех раз выше, чем у виртуальных машин, а на одном сервере вполне может размещаться несколько сотен контейнеров. Столь высокая плотность — одна из главных причин популярности контейнеров на рынке хостинга виртуальных выделенных серверов (VPS). Если на одном и том же сервере можно создать в три раза больше VPS, то в расчете на один VPS затраты снижаются на 66%, что для такого низкомаржинального бизнеса, как хостинг, иногда равно разнице между убыточностью и прибыльностью.
Конечно, не все идеально в мире контейнеров. Например, из-за совместного использования ядра на одном сервере нельзя запускать разные гостевые ОС (например, на системе с Linux-контейнерами невозможно запустить FreeBSD или Windows, но разные дистрибутивы Linux -сколько угодно). Поэтому Windows и Linux на одном и том же сервере (что для гипервизоров не проблема) не работают. Однако по крайней мере в случае Linux этот недостаток можно смягчить за счет использования интерфейсов ABI и библиотек: благодаря этому появляется возможность запускать на одном сервере контейнеры с различными дистрибутивами Linux, но одновременно сокращается общая для этих контейнеров часть ресурсов. В максимальной же степени преимущества контейнеров проявляются в однородной среде.
ИСТОРИЯ КОНТЕЙНЕРОВ
В 2005 году компания Google занялась задачей массового предоставления Web-сервисов, а именно искала способ эластичного масштабирования ресурсов в своем центре обработки данных, чтобы каждый пользователь имел возможность получить достаточный уровень сервиса в любой момент, независимо от текущей загрузки, а оставшиеся ресурсы можно было использовать для служебных фоновых задач.
Поэкспериментировав с традиционной виртуализацией, сотрудники Google сочли ее не подходящей для решения этой задачи. Главной проблемой стали слишком большие потери производительности (соответственно, плотность оказалась слишком низкой) и недостаточно эластичный отклик для динамического переконфигури-рования системы под изменившуюся нагрузку для массового предоставления Web-сервисов.
Последний пункт очень важен, потому что заранее предсказать, сколько запросов — десятки, сотни тысяч или даже миллионы — будут обслуживать Web-сервисы, невозможно. Но пользователи всегда ждут немедленного отклика (а это означает, что разница между нажатием кнопки и появлением результата на экране должна быть незаметна для глаз) независимо от того, сколько именно других людей в этот же момент работают с сервисом. Среднее время загрузки гипервизорной виртуальной машины — десятки секунд, поэтому такой тип виртуализации не подходит для этой задачи.
В то же самое время одна группа разработчиков экспериментировала с Linux и концепцией, основанной на механизме cgroups — так называемые контейнеры процессов. Google наняла этих специалистов для работы над контейнеризацией своих ЦОД с целью решения проблемы эластичности при масштабировании. В январе 2008 года часть технологии cgroup, используемой Google, была перенесена в ядро Linux. Так родился проект LinuX Containers (LXC). Тем временем Parallels выпустила версию своей виртуализации Virtuozzo с открытым исходным кодом под названием OpenVZ. В 2011 году Google и Parallels пришли к соглашению о сотрудничестве в области контейнерных технологий. Результатом стал релиз ядра Linux версии 3.8, представленный в 2013 году. В нем были объединены все актуальные на тот момент контейнерные технологии для Linux, что позволило избежать повторения болезненного разделения ядер, как в случае с KVM и Хеп.
Оставить свой ответ: