Частотный профиль английского и немецкого языка
Чтобы преуспеть в интуитивном методе дешифровки одноалфавитных подстановок, рекомендуется наглядно представить себе «частотный профиль» рассматриваемого языка.
В английском языке частотный профиль показывает заметный е-пик и немного меньший a-пик. Имеется также заметное возвышение хребта r-s-t и еще два хребта поменьше l-m-n-о и h-i.

В немецком языке частотный профиль довольно похож, но е-пик выделяется сильнее, имеется хребет пошире r-s-t-u и еще один хребет пошире f-g-h-i.
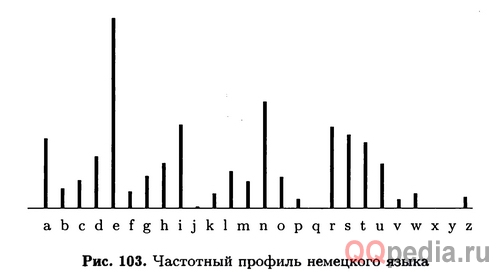
Оба языка показывают j-k впадину, p-q впадину и очень заметную низменность v-w-x-y-z. Различия между любыми большими европейскими языками (вроде французского, итальянского или испанского) не больше, чем между английским и немецким. В романских языках a-пик более заметен и есть изолированный i-пик. На взгляд они довольно похожи.
Изъяны частотного упорядочения. Теоретически этот метод должен был бы работать — по крайней мере для достаточно длинных текстов — достаточно длинных для того, чтобы немногочисленные липограммы, которые там могут существовать, утонули в массе «нормальных» текстов. Но пример, приведенный в разд. 15.2, приводит к полифонической ситуации, даже если известны верные частоты букв открытого текста, что показывает фундаментальную ограниченность* этой процедуры: существует много букв открытого текста с одной и той же частотой, и тогда выбор является недетерминированным.
Более того, даже длинные тексты обычно показывают значительные колебания частот символов. Поэтому «распределение частот» английского языка — фикция, и в лучшем случае в военном, дипломатическом, коммерческом или литературном подъязыках имеет место определенная однородность; действительно, даже один и тот же человек может разговаривать на разных «английских» языках в зависимости от окружения. Соответственно, статистака на частоты букв в различных языках совершенно различна. Кроме того, большинство старых подсчетов основывались на текстах, содержащих не более 10 000 букв. И по вопросу о частотной упорядоченности уже имеется большое расхождение в литературе.
Для английского языка
eaoidhnrstuycfglmwbkpqxz (Е. А. Рое, 1843)
etaoinshrdlucmfwypvbgkqjxz (О. Mergenthaler, 1884)
etoanirshdlcfumpywgbvkxjqz (Р. Valerio, 1893)
etaonisrhldcupfmwybgvkqxjz (Н. F. Gaines, O.P. Meaker, 1939)
etoanirshdlcwumfygpbvkxqjz (L.D. Smith, 1943)
etoanirshdlufcmpywgbvkxzjq (L. Sacco, 1951)
etaonirshdlucmpfywgbvjkqxz (D.Kahn, 1967)
etaonrishdlfcmugpywbvkxjqz (A. G. Konheim, 1981)
etaoinsrhldcumfpgwybvkxjqz (С. H. Meyer, S. M. Matyas, 1982)
Для французского языка
eusranilotdpmcbvghxqfjyzkw (Ch. Vesin de Romanini, 1840)
ensautorilcdvpmqfgbhxyjzkx (F. W. Kasiski, 1863)
esriantouldmcpvfqgxjbhzykw (A. Kerckhoffs, 1883)
easintrulodcpmvqfgbhjxyzkw (G. de Viaris, 1893)
enairstuoldcmpvfbgqhxjyzkw (P. Valerio, 1893, M. Givierge, 1925)
eaistnrulodmpcvqgbfjhzxykw (H. F. Gaines, 1939)
etainroshdlcfumgpwbyvkqxjz (Ch. Eyraud, 1953)
Для немецкого языка
enrisdutaghlobmfzkcwvjpqxy (Ch. Vesin de Romanini, 1840)
enirsahtudlcgmwfbozkpjvqxy (F. W. Kasiski, 1863)
enirstudahgolbmfzcwkvpjqxy (E. B. Fleissner von Wostrowitz, 1881)
enritsduahlcgozmbwfkvpjqxy (P. Valerio, 1893)
enrisatdhulcgmobzwfkvpjyqx (F. W. Kaeding, 1898)
enritsduahlcgozmbwfkvpjyqx (M. Givierge, 1925)
enirstudahgolbmfczwkvpjqxy (A.Figl, 1926)
enirsadtugholbmcfwzkvpjyqx (H. F. Gaines, J. Arthold, 1939)
enristudahglocmbzfwkvpjqxy (L. D. Smith, 1943)
enritsudahlcgozmbwfkvpjqxy (L. Sacco, 1951)
enisrtahduglcofmbwkzvpjyqx (Ch. Eyraud, 1953)
enristdhaulcgmobzwfkvupaojyqx (K. Kiipfmiiller, H. Zemanek, 1954)
enisratduhglcmwobfzkvpjqxy (W. Jensen, 1955)
enisratdhulcgmobwfkzpvjyxq (A. Beutelspacher, 1987)
enirsatdhulgocmbfwkzpvjyxq (F. L. Bauer, 1993)
Подсчет, произведенный Кюпфмюллером и Земанеком, включающий модифицированные гласные, является криптологически несколько неуместным и приводится здесь просто для сравнения. Аналогичные таблицы для итальянского, испанского, датского и латинского языков можно найти в книге Ланга и Судара, 1935 г.
Частотное распределение в английском языке было отражено уже в длине символов кода Морзе, используемого на телеграфе — Морзе подсчитал литеры в ящике типографского шрифта и нашел там 12000 /е/, 9 000 /Ь/, 8 000 /а/, /i/, /п/, /о/, /s/, 6 400 /Ь/. По техническим причинам распределение частот букв английского языка также влияет на распределение клавиш пишущей машинки LINOTYPE Оттмара Мергенталера (1854-1899 гг.).

Гипотетические вероятности символов стохастической выборки из английского и немецкого текстов
")
Девятнадцать наиболее частых английских биграмм (частоты в %%)
")
Восемнадцать наиболее частых немецких биграмм (частоты в %%)
")
98 наиболее частых английских триграмм (частоты в %%)
")
112 наиболее частых немецких триграмм (частоты в %%)
Источник: Ф. Бауэр. Расшифрованные секреты
Оставить свой ответ: